Le code ASCII.
Au début était le texte.
Nous n'avons pas le choix, nous devons adopter une convention qui associera un nombre à un symbole d'écriture, puisque nous disposons de machines qui ne savent manipuler que des nombres. Nous créerons ainsi une table d'équivalence entre des valeurs numériques et des symboles d'écriture. Toutes les parties qui communiqueront entre elles en adoptant la même convention arriveront donc, en principe, à se comprendre.
 |
Figurez-vous que l'informatique n'a pas toujours été aussi
compliquée. Voici un exemple de terminal informatique fort courant à une
certaine époque .
Cette magnifique bestiole, appelée "télétype" du nom de l'entreprise qui la fabriquait (Les moins de 35 ans ne peuvent pas connaître, la machine date de 1967), servait à dialoguer avec un ordinateur, par le truchement d'une liaison série RS232, que nous connaissons toujours, même si ses jours sont désormais comptés. En ces temps reculés de l'informatique, le tube cathodique n'était pas un périphérique courant. On utilisait volontiers à la place une imprimante, le plus souvent à boule ou à marguerite. Cette machine disposait par ailleurs d'un lecteur/perforateur de ruban en papier (trou/pas trou -> 1/0). Mais pour intéressantes qu'elles soient, ces considérations archéologiques nous écartent de notre sujet initial... |
La liaison RS232 prévoit de transmettre en série (bit par bit) un mot de 8 bits en utilisant le bit de poids le plus fort (bit 7) comme bit de parité, pour effectuer un contrôle de validité de la donnée. Le principe est simple : dans un octet, le bit de parité est ajusté de manière à ce que le nombre de 1 soit toujours pair (ou impair, ça dépend de la convention adoptée).
Dans ce cas de figure, il n'y a que 7 bits (b0 à b6) qui sont significatifs d'une donnée, le dernier bit servant juste à ajuster la parité.
7 bits pour un caractère.
"L' American Standard Code for Information Interchange" (ASCII) s'est donc ingénié à coder chaque caractère d'une machine à écrire sous la forme d'une combinaison de 7 bits. En décimal, ça nous donne des valeurs comprises entre 0 et 127.
Comme la base binaire (0 ou 1), si elle est très commode pour un calculateur électronique, l'est beaucoup moins pour le cerveau humain, nous allons utiliser une autre base qui, si elle n'est guère plus "parlante", offre tout de même l'avantage d'aboutir à une écriture beaucoup plus compacte. Cette base devra être une puissance de 2, la plus courante étant la base hexadécimale, parce que chaque "digit" hexadécimal va représenter une combinaison de 4 bits :
| 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
Mais on peut aussi utiliser de l'octal, sur trois bits.
Pourquoi pas la base 10 à laquelle nous sommes habitués depuis notre plus tendre enfance ? Parce que, malheureusement, 10 n'est pas une puissance de 2 et qu'un "digit" décimal ne représente donc pas toutes les combinaisons que l'on peut faire avec un groupe de n bits. 4 c'est trop (hexadécimal) et 3 c'est pas assez (octal). Plus mathématiquement, on ne peut pas trouver de valeur entière de n telle que 10=2n. Essayez donc de résoudre n=Log(10)/Log(2).
Certains ont mis en oeuvre un codage appelé BCD (Binary Coded Decimal). Le principe est simple : chaque "digit" décimal (de 0 à 9) est codé sur un quartet. Certaines combinaisons de bits sont donc impossibles.
- 9 va donner 1001
- 10 donnera 0001 0000 et non pas 1010
Mais revenons à notre code ASCII ; 7 bits sont-ils suffisants ? Oui et non...
D'abord, dans une machine à écrire, il n'y a pas que des caractères imprimables. Il y a aussi des "caractères de contrôle", comme le saut de ligne, le retour chariot, le saut de page, la tabulation, le retour arrière... Tous ces caractères doivent aussi être codés pour que l'ordinateur puisse efficacement piloter une imprimante.
De plus, pour transmettre convenablement un texte, il faudra quelques sémaphores pour indiquer par exemple quand commence le texte, quand il finit...
Enfin, suivant les langues, même lorsqu'elles exploitent l'alphabet latin, certaines lettres sont altérées différemment. L'anglais n'utilise pas d'accents mais la plupart des autres langues les exploitent plus ou moins parcimonieusement.
Au final, si 7 bits suffisent généralement pour une langue donnée, éventuellement en faisant l'impasse sur certains symboles peu usités comme [ ou ], nous ne pourrons pas coder l'ensemble des caractères nécessaires pour la totalité des langues utilisant l'alphabet latin.
La norme iso-646 définit un code ASCII sur 7 bits. Ce code, parfaitement adapté à l'anglais US, l'est moins pour les autres langues. Nous assistons donc à la création d'une multitude de "dialectes ASCII", où certains caractères sont remplacés par d'autres suivant les besoins locaux. Les lecteurs les plus "anciens" se rappelleront peut-être des configurations hasardeuses de certaines imprimantes pour arriver à ce qu'elles impriment en français lisible...
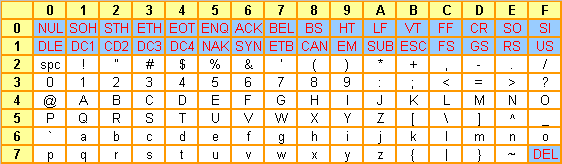 ASCII US défini par la norme iso-646 |
Les "caractères" sur fond bleu
sont les caractères non imprimables.
Pour bien lire le tableau, il faut construire le code hexadécimal en prenant d'abord le digit de la ligne, puis le digit de la colonne. Par exemple, la lettre "n" a pour code hexadécimal 6E |
Comme vous le constatez, il n'y a aucune lettre accentuée dans ce codage. Ce dernier a donc été joyeusement "localisé" pour satisfaire aux exigences des divers pays utilisant l'alphabet latin. Cette situation aboutit rapidement à une impasse, les fichiers ainsi construits n'étant plus exportables dans d'autres pays. De plus, vous constaterez aisément que l'ajout de caractères supplémentaires (le "é", le "ç", le "à" etc.) implique obligatoirement la suppression d'autres caractères (le "[", le "]", le "#" etc.). Ceux qui ont quelques notions de programmation comprendront à quel point c'est facile d'écrire du code avec un jeu de caractères amputé de ces symboles. Dans la pratique, les programmeurs sont condamnés à utiliser un clavier US.
Pour un bit de plus.
Avec les avancées de la technique, le huitième bit qui servait pour le contrôle de parité, contrôle rendu de plus en plus inutile, va être utilisé pour coder plus de caractères. Deux fois plus, finalement.
Ainsi, le codage "iso-latin-1", également connu sous le nom de "iso-8859-1" propose à peu près le codage suivant
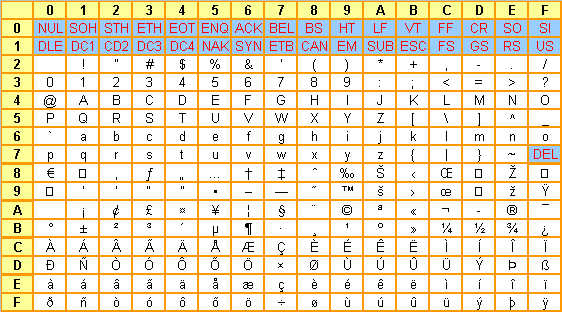 |
Comme vous pouvez le constater ici :
|
Pourquoi "à peu près" ? Le codage ci dessus est une interprétation de la norme iso-8859-1 par notre cher Microsoft qui a un peu bricolé pour ajouter quelques symboles de plus, dont celui de l'euro... La conséquence en est qu'une fois de plus, Windows n'est compatible qu'avec lui-même. Fort heureusement, nous verrons qu'il demeure possible d'adopter un codage plus officiel avec les applications communicantes, mais avec des limites. Notez que si l'on peut reprocher à Microsoft de ne pas suivre les normes, il faut aussi reprocher aux normes d'êtres imparfaites et assez peu réactives.
Pour ajouter à la complexité, la norme iso-8859 définit pas moins de 15 versions différentes, pour satisfaire à tous les besoins mondiaux. A titre d'information, la norme iso-8859-15 devrait pouvoir être utilisée pour l'Europe de l'Ouest avec plus de "bonheur" que l'iso-8859-1.
Finalement, ce bit de plus ne fait que déplacer le problème sans toutefois l'éliminer, nous ne disposons toujours pas d'un système normalisé universel.
Les as de la confusion.
Croyez-vous que la situation est suffisamment confuse comme ça ? Vous vous trompez ! D'autres choses existent, souvent venant de chez IBM.
EBCDIC.
Je me contenterai de vous citer la définition issue du "jargon français" :
Extended Binary Coded Decimal Interchange Code.
Jeu de caractères utilisé sur des dinosaures
d'IBM. Il
existe en 6 versions parfaitement incompatibles entre elles, et il y manque pas
mal de points de ponctuation absolument nécessaires dans beaucoup de langages
modernes (les caractères manquants varient de plus d'une version à l'autre...)
IBM est accusé d'en avoir fait une tactique de contrôle des utilisateurs. (©
Jargon File 3.0.0).
Il existe quelques "moulinettes" capables de convertir tant bien que mal des fichiers codés sous cette forme en fichiers ASCII.
Bien que l'EBCDIC soit aujourd'hui tout à fait confidentiel, puisqu'il ne concerne que les vieilles machines IBM, il faut en tenir compte pour les échanges de données inter plateformes, jusqu'à extinction totale de la race (nous ne devons plus en être très loin).
Pages de codes 437 et 850.
Lorsque IBM a créé le PC (Personal Computer, faut-il le rappeler ?), des jeux de caractères ont été créés sur 8 bits, spécifiquement pour ces machines. Ci-dessous la page de code 437 (CP437). Attention, ce tableau se lit dans l'autre sens, le quartet de poids faible est celui de la ligne et le quartet de poids fort est celui de la colonne.

Tous les petits "grigris" à partir du code B0 étaient destinés à faire de l'art ASCII étendu. De jolies interfaces pseudo graphiques sur des terminaux en mode texte.
Si cette page de code est compatible avec l'ASCII US 7 bits (iso-646) il n'en est rien pour le reste, avec aucune iso-8859. Cette situation a été assez pénalisante, aux débuts de Windows, où l'on devait souvent jongler avec les fichiers issus d'applications DOS et Windows.
Reconstruire la tour de Babel.
Et si l'on construisait une table de codage sur 16 bits ? Là, on aurait de la place pour entrer dans une seule et unique table tous les symboles que l'espèce humaine a pu inventer...
Rassurez-vous, on y a déjà pensé et le projet fait même l'objet d'une normalisation, iso-10646-1.
Compte tenu des difficultés rencontrées pour normaliser des codes sur 8 bits, je vous laisse imaginer ce que ça risque de donner avec 16... De plus, les fichiers de texte verront subitement leur taille doubler pour dire la même chose...
La solution n'est peut-être pas là non plus. Bien que cette norme (plus connue sous le nom d'unicode ou utf-8) existe, elle n'est que peu utilisée.
Conclusion provisoire.
Comme vous le voyez, nous sommes encore loin de disposer d'un système de codage efficace des divers symboles utilisés dans le monde pour communiquer. La situation parait déjà assez désespérée, mais rassurez-vous, nous n'avons pas encore tout vu...
Note:
Les passionnés de la chose trouveront ici beaucoup de détails sur les divers codages existants.